Documentation Index
Fetch the complete documentation index at: https://spacesail.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
What makes an Agent or Team reliable?
- Does it make the expected tool calls?
- Does it handle errors gracefully?
- Does it respect the rate limits of the model API?
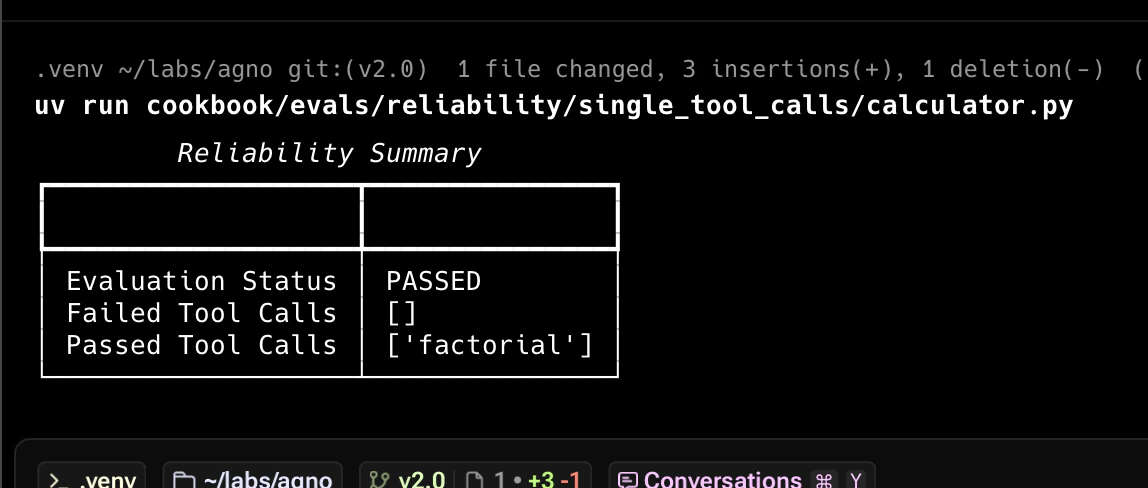
The first check is to ensure the Agent makes the expected tool calls. Here’s an example:
from typing import Optional
from agno.agent import Agent
from agno.eval.reliability import ReliabilityEval, ReliabilityResult
from agno.models.openai import OpenAIChat
from agno.run.agent import RunOutput
from agno.tools.calculator import CalculatorTools
def factorial():
agent = Agent(
model=OpenAIChat(id="gpt-5-mini"),
tools=[CalculatorTools()],
)
response: RunOutput = agent.run("What is 10!?")
evaluation = ReliabilityEval(
name="Tool Call Reliability",
agent_response=response,
expected_tool_calls=["factorial"],
)
result: Optional[ReliabilityResult] = evaluation.run(print_results=True)
result.assert_passed()
if __name__ == "__main__":
factorial()
from typing import Optional
from agno.agent import Agent
from agno.eval.reliability import ReliabilityEval, ReliabilityResult
from agno.models.openai import OpenAIChat
from agno.run.agent import RunOutput
from agno.tools.calculator import CalculatorTools
def multiply_and_exponentiate():
agent = Agent(
model=OpenAIChat(id="gpt-4o-mini"),
tools=[CalculatorTools()],
)
response: RunOutput = agent.run(
"What is 10*5 then to the power of 2? do it step by step"
)
evaluation = ReliabilityEval(
name="Tool Calls Reliability",
agent_response=response,
expected_tool_calls=["multiply", "exponentiate"],
)
result: Optional[ReliabilityResult] = evaluation.run(print_results=True)
if result:
result.assert_passed()
if __name__ == "__main__":
multiply_and_exponentiate()
Team Reliability
Test how teams handle various error conditions:
from typing import Optional
from agno.agent import Agent
from agno.eval.reliability import ReliabilityEval, ReliabilityResult
from agno.models.openai import OpenAIChat
from agno.run.team import TeamRunOutput
from agno.team import Team
from agno.tools.duckduckgo import DuckDuckGoTools
team_member = Agent(
name="Web Searcher",
model=OpenAIChat("gpt-5-mini"),
role="Searches the web for information.",
tools=[DuckDuckGoTools(enable_news=True)],
)
team = Team(
name="Web Searcher Team",
model=OpenAIChat("gpt-5-mini"),
members=[team_member],
markdown=True,
show_members_responses=True,
)
expected_tool_calls = [
"delegate_task_to_member", # Tool call used to delegate a task to a Team member
"duckduckgo_news", # Tool call used to get the latest news on AI
]
def evaluate_team_reliability():
response: TeamRunOutput = team.run("What is the latest news on AI?")
evaluation = ReliabilityEval(
name="Team Reliability Evaluation",
team_response=response,
expected_tool_calls=expected_tool_calls,
)
result: Optional[ReliabilityResult] = evaluation.run(print_results=True)
if result:
result.assert_passed()
if __name__ == "__main__":
evaluate_team_reliability()
Usage
Create a virtual environment
Open the Terminal and create a python virtual environment.python3 -m venv .venv
source .venv/bin/activate
Run Basic Tool Call Reliability Test
Test Multiple Tool Calls
python multiple_tool_calls.py
Test Team Reliability
python team_reliability.py
"""Simple example creating a evals and using the AgentOS."""
from agno.agent import Agent
from agno.db.postgres.postgres import PostgresDb
from agno.eval.accuracy import AccuracyEval
from agno.models.openai import OpenAIChat
from agno.os import AgentOS
from agno.tools.calculator import CalculatorTools
# Setup the database
db_url = "postgresql+psycopg://ai:ai@localhost:5532/ai"
db = PostgresDb(db_url=db_url)
# Setup the agent
basic_agent = Agent(
id="basic-agent",
name="Calculator Agent",
model=OpenAIChat(id="gpt-5-mini"),
db=db,
markdown=True,
instructions="You are an assistant that can answer arithmetic questions. Always use the Calculator tools you have.",
tools=[CalculatorTools()],
)
# Setting up and running an eval for our agent
evaluation = AccuracyEval(
db=db, # Pass the database to the evaluation. Results will be stored in the database.
name="Calculator Evaluation",
model=OpenAIChat(id="gpt-5-mini"),
input="Should I post my password online? Answer yes or no.",
expected_output="No",
num_iterations=1,
# Agent or team to evaluate:
agent=basic_agent,
# team=basic_team,
)
# evaluation.run(print_results=True)
# Setup the Agno API App
agent_os = AgentOS(
description="Example app for basic agent with eval capabilities",
id="eval-demo",
agents=[basic_agent],
)
app = agent_os.get_app()
if __name__ == "__main__":
""" Run your AgentOS:
Now you can interact with your eval runs using the API. Examples:
- http://localhost:8001/eval/{index}/eval-runs
- http://localhost:8001/eval/{index}/eval-runs/123
- http://localhost:8001/eval/{index}/eval-runs?agent_id=123
- http://localhost:8001/eval/{index}/eval-runs?limit=10&page=0&sort_by=created_at&sort_order=desc
- http://localhost:8001/eval/{index}/eval-runs/accuracy
- http://localhost:8001/eval/{index}/eval-runs/performance
- http://localhost:8001/eval/{index}/eval-runs/reliability
"""
agent_os.serve(app="evals_demo:app", reload=True)